The problem
When classifying data, we often want to map existing data into a higher dimensional space, in order to be able to seperate it with a hyperplane or some “not-too-complicated” structure (in case you are not yet familiar with this approach and its immanent problems of overfitting, etc. read “The Curse of Dimensionality in classification”). However, as we keep increasing dimensions, the computational cost of measuring the similiarity (e.g. with a distance in an Euclidian space) increases as well.
Mathematically speaking, we first have to transform features 

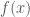


This procedure turns out to be “pretty expensive” (up to impossible) in terms of computational effort. The problem is the mapping into higher dimensional spaces (up to infinite dimensional spaces!), so is there any way to circumvent the computation of
Kernel functions to the rescue!
Let 
Example for given f
Let

Then for the function

the kernel is 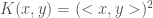
Suppose 
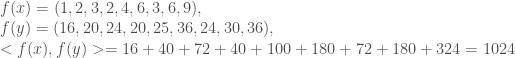
Using the Kernel instead yields:

(example shamelessly stolen from Lili Jiang’s excellent answer on Quora)
